Learnings from deploying Human in the Loop Reinforcement Learning (HIL-SERL) on SO-101
Team: Bruce Kim, Siddharth Saha, Cyan Ding, Indraneel Patil
The Seed Studio lerobot hackathon in Mountain View got us started with the lerobot SO-101 arms from Hugging Face. We initially trained and deployed some VLAs for some simple tasks like picking up popcorn but we quickly realised its limitations:
- The policy would overfit to the exact location of the popcorn or objects that we trained on
- If the workspace changed at all we would have to retrain from scratch
- Training needed a lot of data and manual data collection was not fun
Since physical intelligence recently showed off their policies which they fine tuned with reinforcement learning, we decided to try RL too. Our objective was to try and answer these questions:
- Can we train lerobot to pick up and move objects without any expert trajectories?
- How well do policies transfer from sim to real?
- Can we use imitation learning to initialise a policy and then use reinforcement learning to generalise?
- How does RL extend to fine tuning a VLA model?
The lerobot team had already ported the HIL-SERL algorithm (Human in the loop Sample Efficient Reinforcement Learning) to lerobot with a really a nice guide on how to reproduce the results. Unfortunately the code isnt super well maintained and we had to fix a lot of tiny bugs to set up data collection and training with their code.
Intro to HIL-SERL
HIL-SERL is based on two papers:
- Soft Actor Critic: which is an Off policy maximum entropy RL algorithm with over a 10000 citations. So this algorithm learns a stochastic policy will maximising both entropy as well as expected reward
- RLPD / Reinforcement Learning with prior data: This paper shows how an RL algorithm can be boostrapped with a bunch of expert demonstrations instead of training from scratch
HIL-SERL puts the above two papers together and also adds Human in the loop correction procedure to make learning faster.
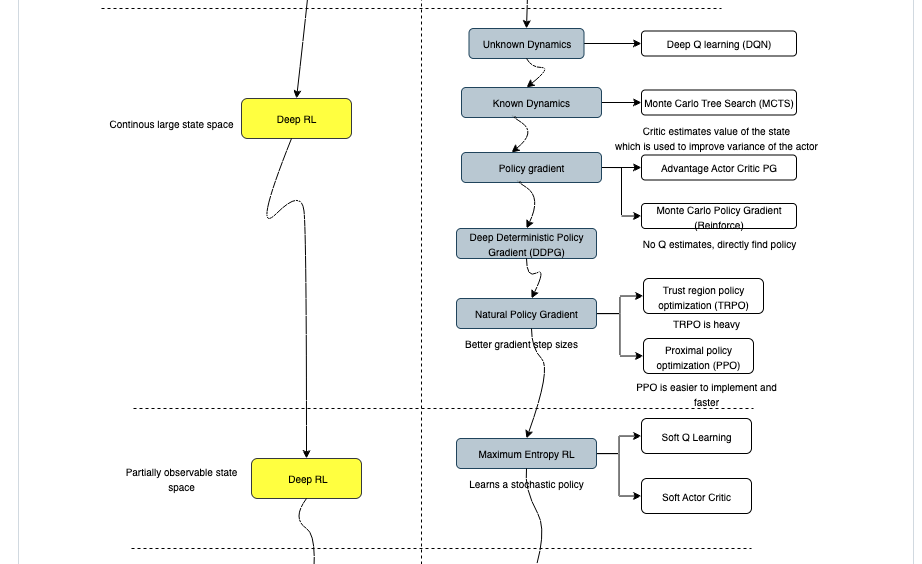
Some surprises after reading the HIL-SERL paper:
- Policy output is in the cartesian end affector space so have to deal with kinematics of the robot
- Separate critic network for the gripper control which is trained separately with DQN (Deep Q learning)
- Separate classification network for generating rewards on the actual robot
- Each task is trained from scratch, does not generalise across tasks although this is pretty typical of RL algorithms
Software Implementation of HIL-SERL
Overall I really like the implementation:
- Clean separation of the actor and the learner
- Modular design of both the actor and the learner
- Can be replicated for many async RL algorithms!
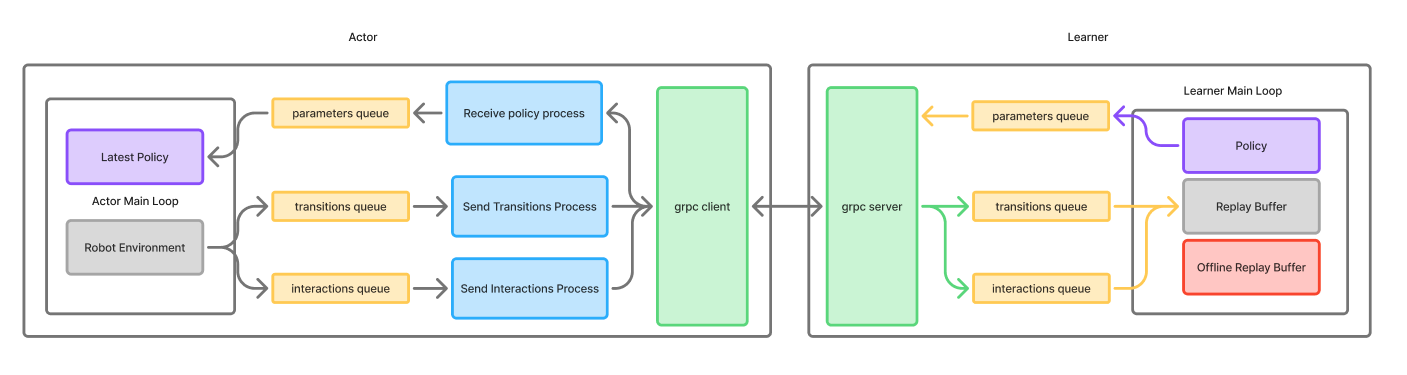
Experiments with HIL-SERL
E0: Running the Mujoco Frankapy Demo
The hugging face team released a Mujoco Frankapy environment where you can run and test the code with some documentation. I remember I had some problems with the keyboard teleop but after minor changes I could get this to work.
Teleop: Keyboard
Robot: Mujoco Frankapy
- Took about 1 hour of rl training to achieve this performance in simulation (on real hardware might take even more time?)
- About 219 episodes
INFO 2025-12-14 17:22:29 /learner.py:589 [LEARNER] Number of optimization step: 23445
E1: Port the demo to SO-101 in Isaac Sim
Why port it to SO-101? We wanted to do some Sim-to-Real experiments so wanted the same robot in simulation.
Why switch from Mujoco to Isaac Sim? Since this algorithm uses real camera images as input, sensor data from Isaac Sim will be more photo realistic than Mujoco giving us better chances of Sim-to-Real
Learning: Isaac Sim has a learning curve. Set up is annoying af, Mujoco is way easier to work with. USD SceneGraph and other concepts are pretty alien. Going through the official tutorials and doing simpler things like spawning a block and stuff helped a lot. I also found a Isaac Sim simulation of SO-101 by LeIsaac. Doing this from scratch would have been tough.
Here I ran into a lot of problems like Mujoco and lerobot works in degrees but Isaac Sim works in radians and in general this was not an easy swap. Looking back this was super useful to just iron out all kinks related to kinematics in sim itself before going to hardware. Increased iteration speed a lot. And going hardware after this step was simply a matter of replacing the sim gym environment with real robot gym environment.
Teleop: Keyboard
Robot: SO-101 Isaac Sim
Signs of Life with HIL-SERL!
- About 1 hour of training with interventions (149 episodes) + 20 episodes in offline buffer
INFO 2026-01-29 22:06:14 /learner.py:565 [LEARNER] Optimization frequency loop [Hz]: 7.837198333881576
INFO 2026-01-29 22:06:14 /learner.py:579 [LEARNER] Number of optimization step: 24205
INFO 2026-01-29 22:06:01 ym_actor.py:349 [ACTOR] Global step 35282: Episode reward: 0.0
INFO 2026-01-29 22:06:01 on/actor.py:363 [ACTOR] Load new parameters from Learner.
INFO 2026-01-29 22:06:01 on/actor.py:386 [ACTOR] Loaded discrete critic parameters from Learner.
E2: First HIL-SERL testing on hardware
We made some changes to enable hardware testing:
- New scripts to replace isaac sim environment with real robot
- Add leader arm teleop instead of keyboard
- Reward signal using keyboard to know if the task succeeded or not
- Added End Affector workspace bounds to make sure robot doesnt collide with anything
- Readd the max_ee_step_m check to 0.05m in the processor
- Set up Cameras, crop images in the environment processors
Teleop: SO-101 Follower
Robot: SO-101 Leader
Either because of camera issues or robot issues, training would keep being interrupted. So I tried to use the resume feature to resume training from a checkpoint everytime the training got interrupted but the model wasnt learning anything after 2 to 3 hours of training.
E3: Testing resume training in simulation
Teleop: Keyboard
Robot: SO-101 Isaac Sim
Updated Isaac Sim to use top camera similar to our hardware setup instead of front camera.Trained picking up the cube for 16 hours, as seen in the video it was pretty comfortably picking up cubes. Then tested the resume feature to ensure it is working -> Turns out there was a bug so I fixed it here (one function was overwriting the path to the policy :()
INFO 2026-02-16 08:01:20 /learner.py:613 [LEARNER] Number of optimization step: 167998
INFO 2026-02-16 08:01:20 /learner.py:598 [LEARNER] Optimization frequency loop [Hz]: 7.549401380420705
INFO 2026-02-16 08:01:20 /learner.py:613 [LEARNER] Number of optimization step: 167999
INFO 2026-02-16 08:01:21 /learner.py:598 [LEARNER] Optimization frequency loop [Hz]: 8.068234477679063
INFO 2026-02-16 08:01:21 /learner.py:613 [LEARNER] Number of optimization step: 168000
But after 16 hours of sim training, the policy looked really good.
Some observations:
- Based on the reward graph the algorithm is definitely learning
- Doesnt experience reward at all without human interventions -> What is the point of RL exactly?
- Takes too long to train because it doesnt see any reward without human interventions, reward conditioning might help but then that doesnt generalise across tasks
- Every few episodes the arm will knock the cube around and then cant recover (Imitation learning was better at this if I remember)
- RL exploration is too naive and random, almost never leads to a reward on its own
- In this form, its impossible to train on hardware from scratch robot will break before this learns anything -> Can we try sim to real?
- Are there any policy learning hyperparameters we can tune to make learning/ RL better?
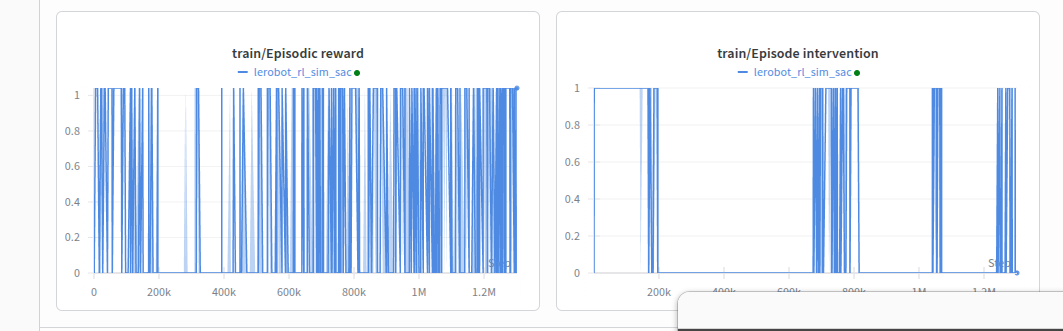
E4: Inference in Sim for picking the cube
We wrote an inference script which just loads the trained checkpoints and runs it in the simulation: This worked well! This was mostly just a smoke test to ensure the inference script is loading the checkpoints correctly before testing on hardware.
E5: One shot inference on hardware for picking the cube
Robot: SO-101 Leader
Then we wrote another script to use the real environment instead: This was a disaster it didnt transfer at all. Video attached but mostly we think the sim to real gap is too high
Sim to Real Gap Notes
- Sim robot is yellow and real robot is black
- Camera mounting isnt exactly the same
- robot calibration isnt shared in sim and real life
- Real life has shadows
- Cube is a darker red
- Wrist camera sees surrounding stuff which it has never seen in sim


E6: RL from a trained checkpoint on hardware
In order to reuse the training from sim, we tried to resume training on real hardware from a checkpoint trained for 16 hours in sim. We wanted to see if this helps learning at all.
Teleop: SO-101 Follower
Robot: SO-101 Leader
Trained for about 4 hours and was able to get some successful picks!
Notes from testing:
- The above is training 16 hours in sim and then fine tuning with RL on hardware for 4 hours : This is pretty crazy It shouldnt take so long to adapt to hardware right? Or is the sim to real gap super high? I am really not sure if the sim training helped at all
- Can we try to achieve the same goal without sim training? Direct training on hardware to see how long it takes? If it takes longer then maybe the sim training helped. During direct training test with expert trajectories on the order of 20-30 in the demo buffer as they recommend starting off with in the paper
- We can also dig into the Soft Actor Critic Algorithm itself and try to tune some knobs to see if we can make training faster
-
Robot does a lot of unecessary exploration in just thin air. We are supposed to define the workspace bounds in HIL SERL, are we defining the workspace bounds too big?
Looks like in the paper demos they manually restrict the workspace bound around the task to perform
TARGET_POSE = np.array([0.553,0.1769683108549487,0.25097833796596336, np.pi, 0, -np.pi/2]) RESET_POSE = TARGET_POSE + np.array([0, 0.03, 0.05, 0, 0, 0]) ABS_POSE_LIMIT_HIGH = TARGET_POSE + np.array([0.03, 0.06, 0.05, 0.1, 0.1, 0.3]) ABS_POSE_LIMIT_LOW = TARGET_POSE - np.array([0.03, 0.01, 0.03, 0.1, 0.1, 0.3]) - It seems like instead of intervening when the policy tries to chase shadows, just giving zero reward seemed to help
- Best intervention policy: Let the policy do as it pleases, if its doing something random then just give 0 reward. To give +1 reward give targeted interventions to keep robot on ideal trajectory and try to give policy control every now and then
E7: RL from scratch with a reduced workspace
Teleop: SO-101 Follower
Robot: SO-101 Leader
To reduce the the number of non relevant actions, this time we enforced a much stricter workspace bound around the cube that we wanted to pick up. We were able to get a working policy in about 40 mins and a slightly generalisable policy in about 2 hours. So our conclusion unfortunately was that sim training didnt help much or at all and a strict workspace bound around the task helps a lot.
Some observations:
- Gripper control training needs to improve: HIL SERL controls the gripper with a separate DQN policy -> Try adding gripper penalty to training -> Can we combine gripper control + ee control into one policy? This might worsen sample efficiency because we are replacing a discrete control dimension by continuous control dimension but worth trying
- Real robot policy also gets confused with shadows? I am actually not sure if the robot is following the shadow or if the shadow is following the robot
- Need to fix this bug: Gripper opens when you start an intervention
-
IL vs RL
- In terms of performance I dont see a whole lot of improvement over IL, if you collect trajectories for 2 hours you will get similar performance with IL
- Data collection is more fun/ less tiring with RL because you are not collecting end to end trajectories just doing interventions
- Data collection is prolly more effective with RL since you are collecting data online instead of offline which should make the policy learn faster
- Resetting environment is still tedious, if we can come up with a reverse policy to keep the block back that would help or just some way of resetting the environment
- Reward classifier? About now we should stop assigning manual rewards (For picking up the cube task we should be able to assign reward just based on robot state I think)
Exploratory Ideas for Future Work
- Does adding depth information make policy convergence faster?
- Experiment with additional robot observations like velocity, motor current
- Can we do longer horizon tasks with a reward curriculum
- How to make use of sim training?
- What about RL in joint space?
- Does this work for out of distribution object positions? What about unseen objects?
- Does adding impedance controller help?
- How well will this work with a dense reward
- How can we make this work without manually defining a narrow workspace bound
Conclusion
HIL-SERL can learn a policy on hardware from scratch within 40 minutes. It enables the policy to collect experience online which makes much more effective data collection possible and so leads to learning an effective policy faster than fine tuning VLAs with imitation learning. Although the narrow workspace bounds needed to make this happen definitely limits the practical applicability of the method. Reusing sim data or sim trained policy also is not trivial considering the large sim to real gap. The policy does not experience reward without interventions for most of the training so RL is probably only useful once policy is good enough to complete the task on its own.
Revisiting the questions we started off with at the start of the project:
- Can we train lerobot to pick up and move objects without any expert trajectories?
- No even HIL-SERL bootstraps with a bunch expert trajectories in the demo buffer and it needs a lot of expert interventions to help the policy experience reward
- How well do policies transfer from sim to real?
- Pretty badly. I did not have a lot of time in debugging what was the main sim to real gap but I suspect its both the sensor data as as well as the actual robot
- Can we use imitation learning to initialise a policy and then use reinforcement learning to generalise?
- This is exactly what the RLPD component of HIL-SERL does. It samples equally from the demo buffer and the replay buffer and helps the policy learn faster
- How does RL extend to fine tuning a VLA model?
- This project did not reach fine tuning a VLA model with RL
Enjoy Reading This Article?
Here are some more articles you might like to read next: